CIRCA:Semantic Web
From CIRCA
Contents |
CIRCA: SEMANTIC WEB
What is the Semantic Web?
The term “Semantic Web” was conceived by Tim Bernes-Lee, the creator of the World Wide Web in the late 90’s as documents on the web grew and many people started figuring out how to organize them and make them accessible and relevant to users. Lee’s original vision was to create a set of machine-readable metadata that as a whole can make the web more intelligent and perhaps even intuitive about how to serve a user's webpage needs. Berners-Lee observed that “search engines index much of the Web's content; they have little ability to select the pages that a user really wants or needs.” He figured out a number of ways in which developers and authors, singly or in collaborations, can use self-descriptions and other techniques to enable context-understanding programs selectively find what users want. Users “tag” or “describe” their web content and help provide ‘meaning’ for their web content.
Much later definitions of the semantic web focused more on the machine, than the user and Berners-Lee defines the Semantic Web as “a web of data that can be processed directly and indirectly by machines.” The machine tags or describes web content independent of the human.
Some Context
At some point in the web’s development, primarily because of how easy it was to throw out HTML pages online, there was a lot of clutter that rendered a lot of people’s keyword searches almost useless and left a lot of researchers scratching their heads. The search engine companies at the time (Yahoo Search/Directories, Alta Vista, Lycos, Infoseek etc.,) were also not helping because they were motivated to rank their highest WebPages on their search results page based on how much a company or a site was willing to pay to be there. They had also had no idea or clue of how to go about tackling the massive keyword abuses used by webmasters to describe the contents of their website, thereby misleading the search engine’s web crawlers and providing inaccurate results when a user searched for an item. There as an absolutely high noise to signal ratio, as it seemed people had to search harder to find just what they wanted. Just about when Google’s innovative PageRank algorithm was about to take off as a better way to sort out the relevance of a web documents on a massive scale, the inventor of the World Wide Web was also mulling over possible solutions to the problem. This informed his motivation behind the semantic web idea. The idea revolved around the possibility of agents being able to understand the semantic content of a document with zero hinting from the author.
Solution seeking a Problem?
There has been a lot of debate as to whether the semantic web is relevant today since Google’s search accuracy and growth has meant people are more satisfied with the types of search results they are now getting. However, Tim Bernes Lee on Wikipedia (Media:http://en.wikipedia.org/wiki/Semantic_Web) has gone ahead to describe the semantic web as “Web 3.0”, implying that it is the next big thing on how data on the internet is organized and accessed. The same Wikipedia article explains that “the internet community as a whole tends to find the two terms "Semantic Web" and "Web 3.0" to be at least synonymous in concept”. However, unlike the simplicity and ubiquity of HTML, the Semantic web is still a complex academic project as someone noted “The average high school kid isn't going to be hacking OWL into his web pages.” But there are niche areas where the Semantic web proves useful, especially when trying to connect the properties of a piece of data from different sources. If Google is suddenly good at organizing web documents according to relevance, the Semantic web wants to go further by looking at how the semantic information in each document is connected to other types of documents (not necessarily web documents) on and off the internet. It attempts to solve the data ambiguity problem. A good example is how Google and most other search engines are unable to aggregate data from the sites they crawl to answer basic questions like:
What are the names of the countries that surround the Mediterranean? What types of animals live in the arctic? Are there any available flights to Rome on Saturday? Which national team won the soccer world cup three years in a row?
To be able to perform such question/answering on search engines requires a level of domain specificity that makes it impractical for general purposes. A geography question/answering (Q&A) system may achieve some level of accuracy with some training (likewise a sports, travel and animal Q&A systems) but the moment one leaves a subject area and asks other types of questions (like asking sports questions on a travel site), the system fails. To complicate matters, some of the most important information is not readily available on the web. Information about travel or finance may be hidden away in proprietary databases. Even if those databases are made searchable, there is no way for current search engines to aggregate this information and tie them together in coherent structures. This is the niche the semantic web also hopes to fill.
Ambiguity
There is a lot of ambiguity about the information that exists on websites because the current web and its tagging technologies are completely unable to provide a full complete detail about the context in which that data exists. Texts on websites and how they are connected together can be ambiguous e.g. how does the machine relate a product item with a price, or determine if any entity A is connected to B? There is also no way to express that these pieces of information are bound together in describing a discrete item, distinct from other items perhaps listed on the page. The Semantic Web addresses this shortcoming, using the descriptive technologies RDF and OWL, and the data-centric, customizable markup language XML. XML provides syntactic interoperability only when both parties know and understand the element names used. If I label an element <price>12.00</price> and someone else labels it <cost>12.00<cost>, there’s no way for a machine to know that those are the same thing without the aid of a separate, highly customized application to map between the elements. For machines to understand data it needs to be gotten in a uniform format, where, for instance, a field labeled “street” always has the same format and contains the same type of information, and so on.
CONCEPTS IN THE SEMANTIC WEB
Resource Descriptive Framework (RDF)
A great deal of the description of the semantic web is also an explanation of the resource description framework it uses to identify objects and their properties. The RDF has subcomponents of course but we will only glean on some of them. From the official site W3C site (http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/#dfn-rdf-graph) RDF is explained as a way to “facilitate operation at Internet scale, RDF is an open-world framework that allows anyone to make statements about any resource.” This consequently, may not prevent people from making nonsensical and inconsistent descriptions about the resources they are identifying. RDF is described as consisting of concepts that include:
i. Graph data model ii. URI-based vocabulary iii. Datatypes iv. Literals v. XML serialization syntax vi. Expression of simple facts vii. Entailment
The Graph data model was also influenced by John Sowa’s Conceptual Graphs. When you visit this site: [[1]], Lee goes on to describe how similar Sowa’s Conceptual Graphs are to the Semantic Web. Conceptual Graphs (CGs) was designed as a way to represent knowledge in a machine. Since CGs are self-contained applications, Lee discusses “webizing” CGs by giving them a URI—using the addressing system of the world wide web.
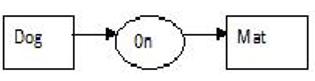
Notice the common expression of an RDF Triple that expresses the relationship between the nodes (subjects and objects) by a predicate (or property).
Media:RDFGraph.jpg
Notice how similar the RDF Graph model is to CG’s display form:
Media:CG.jpg
This can all be reinterpreted in CGs first order logic in the form of:
Linear Form: [Dog]-->(On-->[Mat].
Conceptual Graph Interchange Form: [Dog: *x] [Mat: *y] (On ?x ?y)
Other RDF items from the W3C site and a brief description are provided below:
• A URI reference or literal used as a node identifies what that node represents. A URI reference used as a predicate identifies a relationship between the things represented by the nodes it connects. A predicate URI reference may also be a node in the graph.
• A datatype consists of a lexical space, a value space and a lexical-to-value mapping
• Literals are used to identify values such as numbers and dates by means of a lexical representation. Anything represented by a literal could also be represented by a URI, but it is often more convenient or intuitive to use literals. (A literal may be the object of an RDF statement, but not the subject or the predicate (A literal may be the object of an RDF statement, but not the subject or the predicate)
• RDF uses URI references to identify resources and properties. Certain URI references are given specific meaning by RDF
• RDF provides for XML content as a possible literal value. This typically originates from the use of rdf:parseType="Literal" in the RDF/XML Syntax
RDF Structures
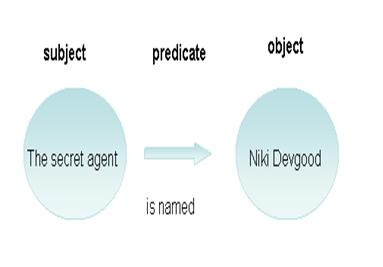
Despite its complexity, RDF is still an XML-based standard for describing resources that exist on the Web, intranets, and extranets. RDF builds on existing XML and URI (Uniform Resource Identifier) technologies, using a URI to identify every resource, and using URIs to make statements about resources. RDF statements describe a resource (identified by a URI), the resource’s properties, and the values of those properties. RDF statements are often referred to as “triples” that consist of a subject, predicate, and object, which correspond to a resource (subject) a property (predicate), and a property value (object). Example:
[resource] [property] [value]
The secret agent is Niki Devgood
[subject] [predicate] [object]
RDF triples can be written with XML tags, and they are often conceptualized graphically.
Media:RDFTriple.jpg
Once triples are defined graphically, they can be coded in either RDF/XML or n-Triples formats to be accessed programmatically.
Media:RDFTriple.jpg
But remember, we are concerned about shortcomings in XML that gives arbitrary tagging decisions to users who might describe their data differently. How do we know that an element label <price> 12.00 </price> is actually related to or same as <cost> 12.00 </cost> if two different people tagged the price of a shoe differently. RDF was supposed to provide a conceptual basis to disambiguate such thorny problems by providing a framework that tries to capture the semantic relationships between data in a web document or elsewhere. For instance, if shoe as a subject property can have an object property price, then it is possible to figure out what other similar object properties might exist for shoe. If cost is also an object property, the framework may want to know if these object properties are synonymous or equivalent to be able to resolve the ambiguity. This is where RDF Schemas become useful.
RDF Schema (RDFS)
RDFS is used to create vocabularies that describe groups of related RDF resources and the relationships between those resources. RDFS triples consist of classes, class properties, and values that define the classes and relationships between the resources within a particular domain. RDF Schemas have the effect of restricting the structure of XML documents. Going back to prior example of elements price and cost in XML tags, one possible way to derive their equivalence is if a schema was designed to identify that price and cost all belong to or are part of a broader class property type money or expense as opposed to belonging to another property class like color for instance. So we could imagine a broad class of items like shoes having class properties like an expense which has an actual monetary value (in our case 12 dollars). This is where the schema needs some additional assistance from an ontological resource to help it understand that price, expense and cost are all part of money which have different types of values.
Web Ontology Language(OWL)
OWL is a third W3C specification for creating Semantic Web applications. Building upon RDF and RDFS, OWL defines the types of relationships that can be expressed in RDF using an XML vocabulary to indicate the hierarchies and relationships between different resources. This hierarchical semantic information is what allows machines to determine the meanings of resources based on their properties and classes. OWL adds more vocabulary for describing these properties and classes: among others, relations between classes (e.g. disjointness), cardinality (e.g. "exactly one"), equality, richer typing of properties, characteristics of properties (e.g. symmetry), and enumerated classes.
The Semantic Media Wiki
One approach many researchers have adopted is narrowing their focus on the types of semantic information that can be gleaned from a site like Wikipedia. Apart from text, the category link structure of Wikipedia pages provides a ready ontological structure that can be mined by programs. If a link to a city contains another link to a famous building or site in that city, it is possible for these programs to deduce that building x exists in city y. This is a very rich area of research in Computational Semantics.
Other approaches use the semantic media wiki (http://semantic-mediawiki.org/wiki/Help:SMW_extensions#SMW_OntologyEditor) which hosts a collection resources users can embed in their own wikis. This is further explained by a researcher close to the project: "You can download the Semantic MediaWiki [wikimedia.org] extension right now and add semantics to a wiki. Currently all the links between pages in a MediaWiki have no meaning, and all the facts in each page can only be extracted by humans reading it. With the upgrade a page can state is located in::California to explain the type of relationship implied by a link, and can express attribute values like population:=1,305,736. The current version summarizes all such facts in each page and can export them as RDF. It's a simple extension, but once it's implemented in Wikipedia, you could query for, e.g. the population of every major city in California. Doing such semantic queries using Google is basically impossible, you'll just get a list of pages and have to read and filter each one to create your own list.
Sharing semantics between datastores would require people agreeing on ontologies, which according to people like Clay Shirky [[2]] is indeed a pipe dream. I'm not so sure, that's like saying categories in Wikipedia are useless because they're disorganized. Just using the Dublin Core metadata [dublincore.org] to identify authors of information in a common way would be a big breakthrough, and there are simple enough ways to do it in XHTML that I think it'll pick up steam in the next few years."
However, most other researchers think the Semantic Web is a dead end. What do you think?

{kind=link}
{kind=link}
{kind=link}